

如何用爬虫下载中国土地市场网的土地成交数据?

作为毕业狗想研究下土地出让方面的信息,需要每一笔的土地出让数据。想从中国土地市场网的土地成交结果公告(http://www.landchina.com/default.aspx?tabid=263&ComName=default)中点击每一笔土地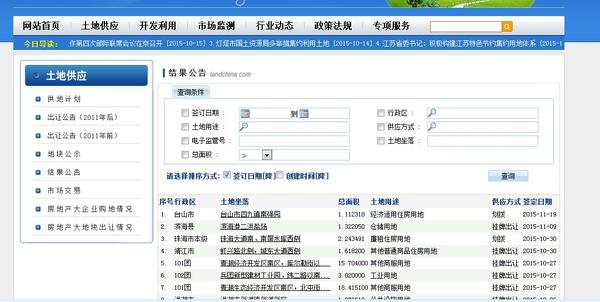 ,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,
,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,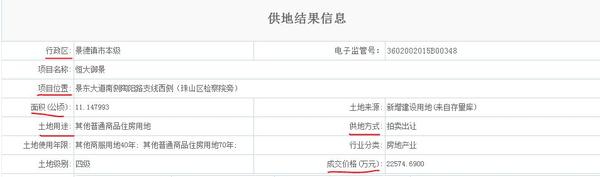 由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
回复内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import random
import sys
def get_post_data(url, headers):
# 访问一次网页,获取post需要的信息
data = {
'TAB_QuerySubmitSortData': '',
'TAB_RowButtonActionControl': '',
}
try:
req = requests.get(url, headers=headers)
except Exception, e:
print 'get baseurl failed, try again!', e
sys.exit(1)
try:
soup = BeautifulSoup(req.text, "html.parser")
TAB_QueryConditionItem = soup.find(
'input', id="TAB_QueryConditionItem270").get('value')
# print TAB_QueryConditionItem
data['TAB_QueryConditionItem'] = TAB_QueryConditionItem
TAB_QuerySortItemList = soup.find(
'input', id="TAB_QuerySort0").get('value')
# print TAB_QuerySortItemList
data['TAB_QuerySortItemList'] = TAB_QuerySortItemList
data['TAB_QuerySubmitOrderData'] = TAB_QuerySortItemList
__EVENTVALIDATION = soup.find(
'input', id='__EVENTVALIDATION').get('value')
# print __EVENTVALIDATION
data['__EVENTVALIDATION'] = __EVENTVALIDATION
__VIEWSTATE = soup.find('input', id='__VIEWSTATE').get('value')
# print __VIEWSTATE
data['__VIEWSTATE'] = __VIEWSTATE
except Exception, e:
print 'get post data failed, try again!', e
sys.exit(1)
return data
def get_info(url, headers):
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
items = soup.find(
'table', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1")
# 所需信息组成字典
info = {}
# 行政区
division = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl").get_text().encode('utf-8')
info['XingZhengQu'] = division
# 项目位置
location = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl").get_text().encode('utf-8')
info['XiangMuWeiZhi'] = location
# 面积(公顷)
square = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl").get_text().encode('utf-8')
info['MianJi'] = square
# 土地用途
purpose = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl").get_text().encode('utf-8')
info['TuDiYongTu'] = purpose
# 供地方式
source = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl").get_text().encode('utf-8')
info['GongDiFangShi'] = source
# 成交价格(万元)
price = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl").get_text().encode('utf-8')
info['ChengJiaoJiaGe'] = price
# print info
# 用唯一值的电子监管号当key, 所需信息当value的字典
all_info = {}
Key_ID = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl").get_text().encode('utf-8')
all_info[Key_ID] = info
return all_info
def get_pages(baseurl, headers, post_data, date):
print 'date', date
# 补全post data
post_data['TAB_QuerySubmitConditionData'] = post_data[
'TAB_QueryConditionItem'] + ':' + date
page = 1
while True:
print ' page {0}'.format(page)
# 休息一下,防止被网页识别为爬虫机器人
time.sleep(random.random() * 3)
post_data['TAB_QuerySubmitPagerData'] = str(page)
req = requests.post(baseurl, data=post_data, headers=headers)
# print req
soup = BeautifulSoup(req.text, "html.parser")
items = soup.find('table', id="TAB_contentTable").find_all(
'tr', onmouseover=True)
# print items
for item in items:
print item.find('td').get_text()
link = item.find('a')
if link:
print item.find('a').text
url = 'http://www.landchina.com/' + item.find('a').get('href')
print get_info(url, headers)
else:
print 'no content, this ten days over'
return
break
page += 1
if __name__ == "__main__":
# time.time()
baseurl = 'http://www.landchina.com/default.aspx?tabid=263'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36',
'Host': 'www.landchina.com'
}
post_data = (get_post_data(baseurl, headers))
date = '2015-11-21~2015-11-30'
get_pages(baseurl, headers, post_data, date)
之前帮老师爬过这个信息,从1995年-2015年有170多万条,算了下时间需要40多个小时才能爬完。我爬到2000年就没有继续爬了。当时写代码的时候刚学爬虫,不懂原理,发现这个网页点击下一页以及改变日期后,网址是不会变的,网址是不会变的,网址是不会变的Orz,对于新手来说根本不知道是为什么。后来就去找办法,学了点selenium,利用它来模拟浏览器操作,更改日期、点击下一页什么的都可以实现了。好处是简单粗暴,坏处是杀鸡用牛刀,占用了系统太多资源。再到后来,学会了一点抓包技术,知道了原来日期和换页都是通过post请求的。今天下午就把程序修改了一下,用post代替了原来的selenium。废话不说,上代码了。
# -*- coding: gb18030 -*-
'landchina 爬起来!'
import requests
import csv
from bs4 import BeautifulSoup
import datetime
import re
import os
class Spider():
def __init__(self):
self.url='http://www.landchina.com/default.aspx?tabid=263'
#这是用post要提交的数据
self.postData={ 'TAB_QueryConditionItem':'9f2c3acd-0256-4da2-a659-6949c4671a2a',
'TAB_QuerySortItemList':'282:False',
#日期
'TAB_QuerySubmitConditionData':'9f2c3acd-0256-4da2-a659-6949c4671a2a:',
'TAB_QuerySubmitOrderData':'282:False',
#第几页
'TAB_QuerySubmitPagerData':''}
self.rowName=[u'行政区',u'电子监管号',u'项目名称',u'项目位置',u'面积(公顷)',u'土地来源',u'土地用途',u'供地方式',u'土地使用年限',u'行业分类',u'土地级别',u'成交价格(万元)',u'土地使用权人',u'约定容积率下限',u'约定容积率上限',u'约定交地时间',u'约定开工时间',u'约定竣工时间',u'实际开工时间',u'实际竣工时间',u'批准单位',u'合同签订日期']
#这是要抓取的数据,我把除了分期约定那四项以外的都抓取了
self.info=[
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl',#0
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl',#1
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r17_c2_ctrl',#2
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl',#3
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl',#4
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c4_ctrl',#5
#这条信息是土地来源,抓取下来的是数字,它要经过换算得到土地来源,不重要,我就没弄了
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl',#6
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl',#7
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c2_ctrl', #8
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c4_ctrl',#9
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c2_ctrl',#10
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl',#11
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c1_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c2_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c3_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c4_0_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r9_c2_ctrl',#12
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r21_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c2',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c4_ctrl']
#第一步
def handleDate(self,year,month,day):
#返回日期数据
'return date format %Y-%m-%d'
date=datetime.date(year,month,day)
# print date.datetime.datetime.strftime('%Y-%m-%d')
return date #日期对象
def timeDelta(self,year,month):
#计算一个月有多少天
date=datetime.date(year,month,1)
try:
date2=datetime.date(date.year,date.month+1,date.day)
except:
date2=datetime.date(date.year+1,1,date.day)
dateDelta=(date2-date).days
return dateDelta
def getPageContent(self,pageNum,date):
#指定日期和页数,打开对应网页,获取内容
postData=self.postData.copy()
#设置搜索日期
queryDate=date.strftime('%Y-%m-%d')+'~'+date.strftime('%Y-%m-%d')
postData['TAB_QuerySubmitConditionData']+=queryDate
#设置页数
postData['TAB_QuerySubmitPagerData']=str(pageNum)
#请求网页
r=requests.post(self.url,data=postData,timeout=30)
r.encoding='gb18030'
pageContent=r.text
# f=open('content.html','w')
# f.write(content.encode('gb18030'))
# f.close()
return pageContent
#第二步
def getAllNum(self,date):
#1无内容 2只有1页 3 1—200页 4 200页以上
firstContent=self.getPageContent(1,date)
if u'没有检索到相关数据' in firstContent:
print date,'have','0 page'
return 0
pattern=re.compile(u'<td.*?class="pager".*?>共(.*?)页.*?</td>')
result=re.search(pattern,firstContent)
if result==None:
print date,'have','1 page'
return 1
if int(result.group(1))<=200:
print date,'have',int(result.group(1)),'page'
return int(result.group(1))
else:
print date,'have','200 page'
return 200
#第三步
def getLinks(self,pageNum,date):
'get all links'
pageContent=self.getPageContent(pageNum,date)
links=[]
pattern=re.compile(u'<a.*?href="default.aspx.*?tabid=386(.*?)".*?>',re.S)
results=re.findall(pattern,pageContent)
for result in results:
links.append('http://www.landchina.com/default.aspx?tabid=386'+result)
return links
def getAllLinks(self,allNum,date):
pageNum=1
allLinks=[]
while pageNum<=allNum:
links=self.getLinks(pageNum,date)
allLinks+=links
print 'scrapy link from page',pageNum,'/',allNum
pageNum+=1
print date,'have',len(allLinks),'link'
return allLinks
#第四步
def getLinkContent(self,link):
'open the link to get the linkContent'
r=requests.get(link,timeout=30)
r.encoding='gb18030'
linkContent=r.text
# f=open('linkContent.html','w')
# f.write(linkContent.encode('gb18030'))
# f.close()
return linkContent
def getInfo(self,linkContent):
"get every item's info"
data=[]
soup=BeautifulSoup(linkContent)
for item in self.info:
if soup.find(id=item)==None:
s=''
else:
s=soup.find(id=item).string
if s==None:
s=''
data.append(unicode(s.strip()))
return data
def saveInfo(self,data,date):
fileName= 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')+'/'+datetime.datetime.strftime(date,'%d')+'.csv'
if os.path.exists(fileName):
mode='ab'
else:
mode='wb'
csvfile=file(fileName,mode)
writer=csv.writer(csvfile)
if mode=='wb':
writer.writerow([name.encode('gb18030') for name in self.rowName])
writer.writerow([d.encode('gb18030') for d in data])
csvfile.close()
def mkdir(self,date):
#创建目录
path = 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')
isExists=os.path.exists(path)
if not isExists:
os.makedirs(path)
def saveAllInfo(self,allLinks,date):
for (i,link) in enumerate(allLinks):
linkContent=data=None
linkContent=self.getLinkContent(link)
data=self.getInfo(linkContent)
self.mkdir(date)
self.saveInfo(data,date)
print 'save info from link',i+1,'/',len(allLinks)
1. 多线程
2. 防止封IP
3. 用Mongdb存储大型非结构化数据
了解更多可以访问探码科技大数据介绍页面:http://www.tanmer.com/bigdata 我抓过这个网站的结束合同,还是比较好抓的。抓完生成表格,注意的就是选择栏的异步地区等内容,需要对他的js下载下来队形异步请求。提交数据即可。请求的时候在他的主页有一个id。好像是这么个东西,去年做的,记不清了,我有源码可以给你分享。用java写的 我是爬虫小白,请教下,不是说不能爬取asp的页面吗?
详细内容页的地址是”default.aspx?tabid=386&comname=default&wmguid=75c725。。。“,网站是在default.aspx页读取数据库显示详细信息,不是说读不到数据库里的数据吗?

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 http状态码520是什么意思
Oct 13, 2023 pm 03:11 PM
http状态码520是什么意思
Oct 13, 2023 pm 03:11 PM
http状态码520是指服务器在处理请求时遇到了一个未知的错误,无法提供更具体的信息。用于表示服务器在处理请求时发生了一个未知的错误,可能是由于服务器配置问题、网络问题或其他未知原因导致的。通常是由服务器配置问题、网络问题、服务器过载或代码错误等原因导致的。如果遇到状态码520错误,最好联系网站管理员或技术支持团队以获取更多的信息和帮助。
 http状态码403是什么
Oct 07, 2023 pm 02:04 PM
http状态码403是什么
Oct 07, 2023 pm 02:04 PM
http状态码403是服务器拒绝了客户端的请求的意思。解决http状态码403的方法是:1、检查身份验证凭据,如果服务器要求身份验证,确保提供正确的凭据;2、检查IP地址限制,如果服务器对IP地址进行了限制,确保客户端的IP地址被列入白名单或未列入黑名单;3、检查文件权限设置,如果403状态码与文件或目录的权限设置有关,确保客户端具有足够的权限访问这些文件或目录等等。
 如何使用Nginx Proxy Manager实现HTTP到HTTPS的自动跳转
Sep 26, 2023 am 11:19 AM
如何使用Nginx Proxy Manager实现HTTP到HTTPS的自动跳转
Sep 26, 2023 am 11:19 AM
如何使用NginxProxyManager实现HTTP到HTTPS的自动跳转随着互联网的发展,越来越多的网站开始采用HTTPS协议来加密传输数据,以提高数据的安全性和用户的隐私保护。由于HTTPS协议需要SSL证书的支持,因此在部署HTTPS协议时需要有一定的技术支持。Nginx是一款强大且常用的HTTP服务器和反向代理服务器,而NginxProxy
 理解网页重定向的常见应用场景并了解HTTP301状态码
Feb 18, 2024 pm 08:41 PM
理解网页重定向的常见应用场景并了解HTTP301状态码
Feb 18, 2024 pm 08:41 PM
掌握HTTP301状态码的含义:网页重定向的常见应用场景随着互联网的迅猛发展,人们对网页交互的要求也越来越高。在网页设计领域,网页重定向是一种常见且重要的技术,通过HTTP301状态码来实现。本文将探讨HTTP301状态码的含义以及在网页重定向中的常见应用场景。HTTP301状态码是指永久重定向(PermanentRedirect)。当服务器接收到客户端发
 快速应用:PHP 异步 HTTP 下载多个文件的实用开发案例分析
Sep 12, 2023 pm 01:15 PM
快速应用:PHP 异步 HTTP 下载多个文件的实用开发案例分析
Sep 12, 2023 pm 01:15 PM
快速应用:PHP异步HTTP下载多个文件的实用开发案例分析随着互联网的发展,文件下载功能已成为很多网站和应用程序的基本需求之一。而对于需要同时下载多个文件的场景,传统的同步下载方式往往效率低下且耗费时间。为此,使用PHP异步HTTP下载多个文件成为了一种越来越常见的解决方案。本文将通过一个实际的开发案例,详细分析如何使用PHP异步HTTP
 使用http.PostForm函数发送带有表单数据的POST请求
Jul 25, 2023 pm 10:51 PM
使用http.PostForm函数发送带有表单数据的POST请求
Jul 25, 2023 pm 10:51 PM
使用http.PostForm函数发送带有表单数据的POST请求在Go语言的http包中,可以使用http.PostForm函数发送带有表单数据的POST请求。http.PostForm函数的原型如下:funcPostForm(urlstring,dataurl.Values)(resp*http.Response,errerror)其中,u
 HTTP 200 OK:了解成功响应的含义与用途
Dec 26, 2023 am 10:25 AM
HTTP 200 OK:了解成功响应的含义与用途
Dec 26, 2023 am 10:25 AM
HTTP状态码200:探索成功响应的含义与用途HTTP状态码是用来表示服务器响应状态的数字代码。其中,状态码200表示请求已成功被服务器处理。本文将探索HTTP状态码200的具体含义与用途。首先,让我们了解一下HTTP状态码的分类。状态码被分为五个类别,分别是1xx、2xx、3xx、4xx和5xx。其中,2xx表示成功的响应。而200是2xx中最常见的状态码
 http请求415错误解决方法
Nov 14, 2023 am 10:49 AM
http请求415错误解决方法
Nov 14, 2023 am 10:49 AM
解决方法:1、检查请求头中的Content-Type;2、检查请求体中的数据格式;3、使用适当的编码格式;4、使用适当的请求方法;5、检查服务器端的支持情况。
