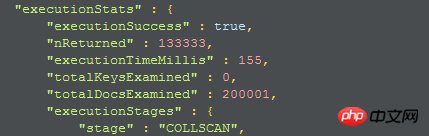
当我直接用find返回全部字段时,结果如下,查询时间为155
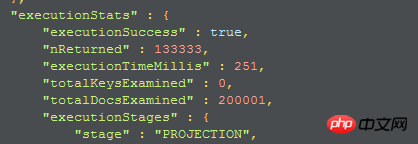
如果限定返回字段,查询时间反而更长了,查询时间为251
为什么?如果我限定返回的字段,查询的字符字节变少,传输不应该更快么?
光阴似箭催人老,日月如移越少年。
您贴出的执行计划主要透露出的信息如下:
1、第一个执行计划:
因为没有使用到索引,所以collscan透露是全collection扫描,所以可以考虑创建索引
2、第二个执行计划:
仍然是全collection扫描,并将满足条件的documents扫描到内存,并在内存中完成projection,选出指定的field,并返回field。这样子看来,时间会消耗的更多。
尽管是只返回指定的field,但是读取存储的时候,全collection扫描的时候,只能返回整个documents。这大概是数据库方面的一些基本原理:按照文档来读写的;补充说明,有些列式数据库是按列保存的,就是您设想的那种情形;但很多数据库是按照行,或者按照文档保存的。
如果您在指定的field上创建covered index,并只返回指定的field,这样子的效率最佳,因为仅仅扫描索引就可以返回指定的field。
供参考。
Love MongoDB! Have fun!






















您贴出的执行计划主要透露出的信息如下:
1、第一个执行计划:
因为没有使用到索引,所以collscan透露是全collection扫描,所以可以考虑创建索引
2、第二个执行计划:
仍然是全collection扫描,并将满足条件的documents扫描到内存,并在内存中完成projection,选出指定的field,并返回field。这样子看来,时间会消耗的更多。
尽管是只返回指定的field,但是读取存储的时候,全collection扫描的时候,只能返回整个documents。这大概是数据库方面的一些基本原理:按照文档来读写的;补充说明,有些列式数据库是按列保存的,就是您设想的那种情形;但很多数据库是按照行,或者按照文档保存的。
如果您在指定的field上创建covered index,并只返回指定的field,这样子的效率最佳,因为仅仅扫描索引就可以返回指定的field。
供参考。
Love MongoDB! Have fun!