
背景:
Python3 下使用 bs4 的 select 去获取 ZOZO首页上方的 coupon 信息中店铺名字。 (国内ip貌似看不到优惠券信息,需要翻一下才能看到,最好是岛国ip)
问题:
发现自己找不到他的店铺名字在写在什么地方,不知道怎么取,前端 js 不懂,请教诸位解答。谢谢。
自己的代码如下:
import requests, bs4
shopName = 'BEAUTY&YOUTH'
url = 'http://zozo.jp/'
def getZozoCoupon():
res = requests.get(url, headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36"})
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
elems = soup.select('.bnrName')
return elems[0].text.strip()如下截图中是想要获取的文字,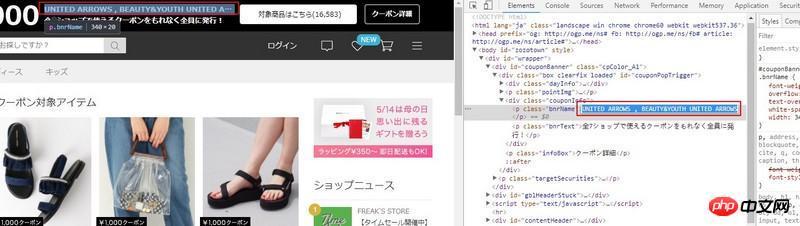
发现查看源码中却没有文字。
<p class="couponInfo">
<p class="bnrName">说好的文字呢。。。</p>
<p class="bnrText"></p>
</p>请教他的文字是在哪实现的啊,要怎么用bs4 select才出来,谢谢。



















有可能用ajax从服务器获取之后操作dom动态添加的吧,在浏览器里执行了js就文字也被添加进来。而你用爬虫爬的时候没有执行有关js所以也没有添加文字。
要是真的这样的话,你可以在浏览器的f12那里查看network,把获取文字的那个http请求的url找出来,直接请求这个url获取你需要的信息。
我在浏览器中打开http://zozo.jp/查看源代码并没有找到你所要找的bnrName

你在浏览器上右键“查看网页源码”看看能不能找得你那段文字,如果找不到,那网页应该是用js或者ajax动态加载的,想要爬取这种动态页面,两种方法,要么是自己手动模拟请求,要么就用selenium去抓吧
确实是js生成的,已经采用headless浏览器模拟抓取了,谢谢大家!