请求地址url是通过firefox查看得到的json的地址,用浏览器可以打开,但是用scrapy爬的时候就被ban了求解决办法。
https://image.baidu.com/searc...
在 settings.py 将 ROBOTSTXT_OBEY = False 试试。
settings.py
ROBOTSTXT_OBEY = False
不要加hearders试试
赞成楼上,如果还会被墙。可采用scrapy+selenium+phantomjs的方式。
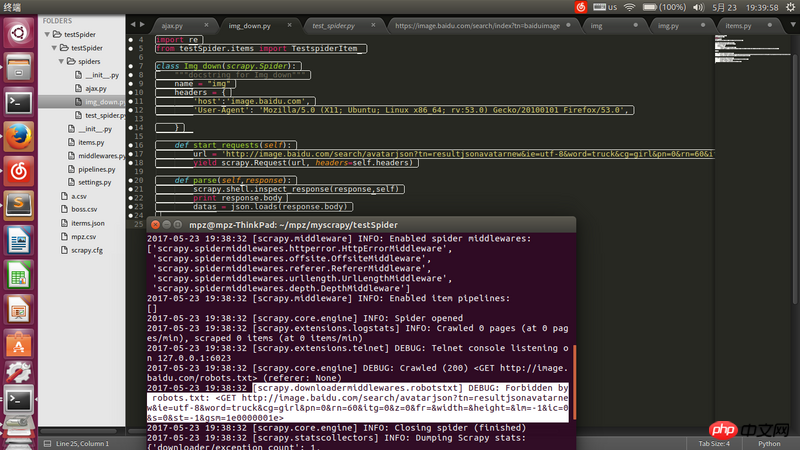




















在
settings.py将ROBOTSTXT_OBEY = False试试。不要加hearders试试
赞成楼上,如果还会被墙。可采用scrapy+selenium+phantomjs的方式。