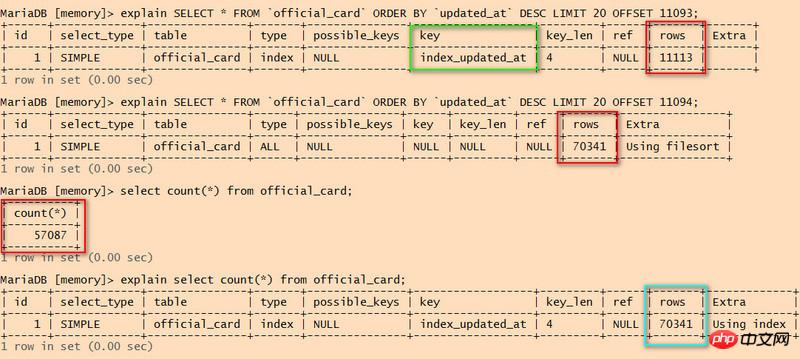
对比前两条语句,第二条没有使用索引,我记得是扫描行数达到一定行数时会放弃使用索引,这个临界值是多少呢?
全表扫描是显示扫描行数是 70341 行,而数据总行数却只有 57087 行?
select count(*) 使用了索引,但是也扫描了 70341 行,这个语句会产生性能问题吗?
CBO优化机制的数据库中,没有明确的使用或不适用索引的临界值,以执行计划中的COST最小为标准,经验值是取表总行数小于5%的时候用索引比较合适。
我理解第二个语句使用的是表的统计数据,如果表最近发生过比较大的变更,统计数据有没有及时更新,会出现两者偏差较大的情况。
count(*)使用了索引,说明update_at字段有NOT NULL的定义,相比较全表扫描,扫描索引的成本会更低一些。



















CBO优化机制的数据库中,没有明确的使用或不适用索引的临界值,以执行计划中的COST最小为标准,经验值是取表总行数小于5%的时候用索引比较合适。
我理解第二个语句使用的是表的统计数据,如果表最近发生过比较大的变更,统计数据有没有及时更新,会出现两者偏差较大的情况。
count(*)使用了索引,说明update_at字段有NOT NULL的定义,相比较全表扫描,扫描索引的成本会更低一些。