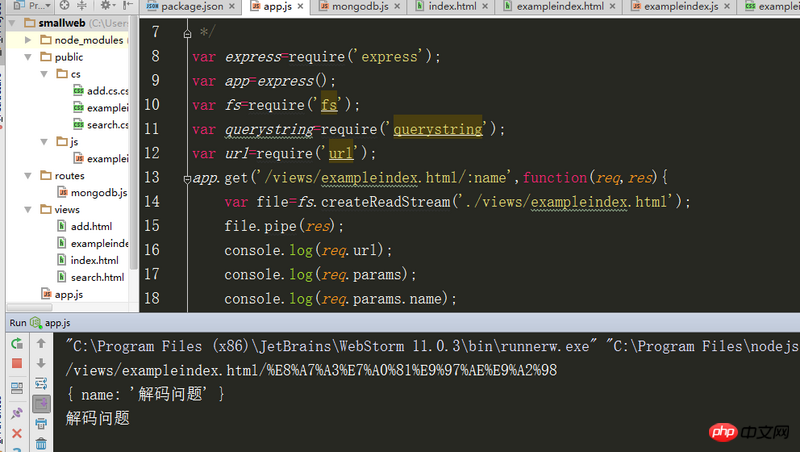
在express4.x中使用req.params读取URL中的参数,当参数为中文时,req.url输出的中文为十六进制,而req.params输出的确是中文,我想问一下使用req.params是不是调用了什么或是默认哪种解码方式
欢迎选择我的课程,让我们一起见证您的进步~~
肯定是UTF-8编码,因为当前官方node仅仅支持UTF-8一种多字节编码方式,utf-8中一个汉字由三个字节构成,你观看url中16进制编码正好是12个字节,通过这个也可以验证。req.body req.query req.params 把转码的多字节都会反转回来。
这个是urlencode。用url-safe的字符集进行编码的。
js里用encodeURI和decodeURI进行编码解码的。其他语言也提供了类似的方法。
encodeURI
decodeURI
encodeURI('解码问题') // => '%E8%A7%A3%E7%A0%81%E9%97%AE%E9%A2%98' decodeURI('%E8%A7%A3%E7%A0%81%E9%97%AE%E9%A2%98') // => '解码问题'
题外
当url中出现不允许出现的字符(例如 空格符),或者字符集是US-ASCII的超集的时候,使用UTF-8编码(极特殊情况,曾使用UTF-16编码,现已不用),使用%XX的形式表示其编码数据。参见标准RFC3986。
%XX
望采纳。





















肯定是UTF-8编码,因为当前官方node仅仅支持UTF-8一种多字节编码方式,utf-8中一个汉字由三个字节构成,你观看url中16进制编码正好是12个字节,通过这个也可以验证。
req.body req.query req.params 把转码的多字节都会反转回来。
这个是urlencode。用url-safe的字符集进行编码的。
js里用
encodeURI和decodeURI进行编码解码的。其他语言也提供了类似的方法。题外
当url中出现不允许出现的字符(例如
%XX的形式表示其编码数据。参见标准RFC3986。望采纳。