
根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?




















再看看上面的错误,是
byte 0xa3byte 0xa3于是我在终端上试了几次,结果发现冒号的gb2312 encode
所以应该就是python拿默认的utf-8来decode gb2312的body, 所以我能想到的一个办法就是修改默认编码值,也就是第一行的声明:
所以应该就是python拿默认的utf-8来decode gb2312的body, 所以我能想到的一个办法就是修改默认编码值,也就是第一行的声明:# -*- coding: gb2312 -*-于是我在终端上试了几次,结果发现冒号的gb2312 encoderrreee
# -*- coding: gb2312 -*-🎜然后运行果然成功,请问还有没有别的方法?🎜Python3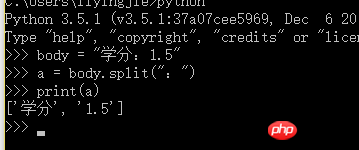
decode后,body应该是unicode编码,使用下面的方式即可:
又是一个编码的问题,可以参考:人机交互之字符编码和 五分钟战胜 Python 字符编码。