我想抓取此网站的实时黄金价格,http://goldprice.org/live-gol...我发现它一直用ajax传送实时数据,可以看到,每次都会生成不同的sessionid,这个sessionid是本地生成的吗,又该怎么获得?有了sessionid后,是否需要post全部的信息?
光阴似箭催人老,日月如移越少年。
看了一下网站,好像没有发现sessionid实时更新。
你可以先从网页上拿一个最新的sessionid,然后保证和ajax请求一样的参数实时去获取数据。自己定一个时间,例如每一个小时,你的请求sessionid参数用当前返回的最新sessionid来替换进行请求,如此循环。
requests模块,先请求一下,然后第二次请求就自己会带上session了
s = requests.Session() s.get('http://httpbin.org/cookies/set/sessioncookie/123456789') r = s.get("http://httpbin.org/cookies") print(r.text) # '{"cookies": {"sessioncookie": "123456789"}}'

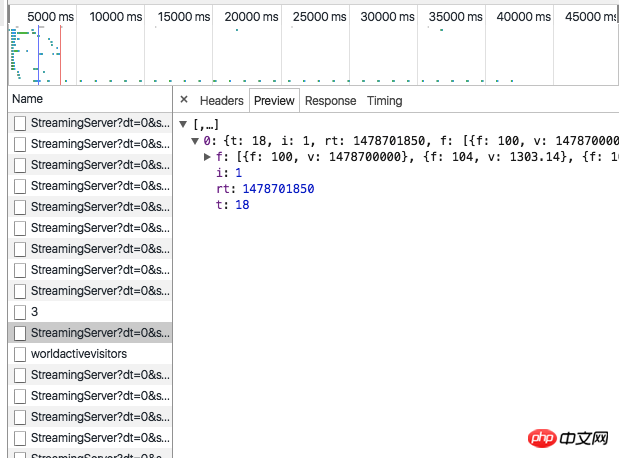
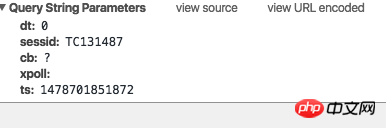



















看了一下网站,好像没有发现sessionid实时更新。
你可以先从网页上拿一个最新的sessionid,然后保证和ajax请求一样的参数实时去获取数据。自己定一个时间,例如每一个小时,你的请求sessionid参数用当前返回的最新sessionid来替换进行请求,如此循环。
requests模块,先请求一下,然后第二次请求就自己会带上session了