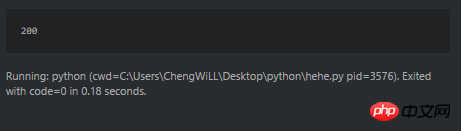
import urllib2 opener = urllib2.build_opener() html = None response = None response = opener.open('http://www.sxxrcs.com/was5/web/') html = response.code print html
比如这个爬虫,输出状态码是200。
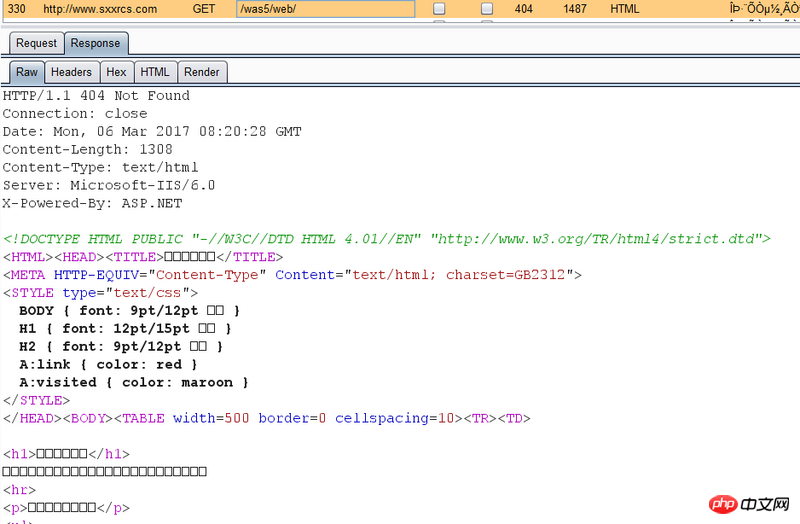
可是直接访问http://www.sxxrcs.com/was5/web/是404,抓包响应的也是404,请问这是为什么?
人生最曼妙的风景,竟是内心的淡定与从容!
用requests吧
import requests r = requests.get('http://www.sxxrcs.com/was5/web/') print r.status_code print r.text
200正常啊,requests方便快捷。




















用requests吧
200正常啊,requests方便快捷。