
日志就是按照时间顺序追加的、完全有序的记录序列,其实就是一种特殊的文件格式,文件是一个字节数组,而这里日志是一个记录数据,只是相对于文件来说,这里每条记录都是按照时间的相对顺序排列的,可以说日志是最简单的一种存储模型,读取一般都是从左到右,例如消息队列,一般是线性写入log文件,消费者顺序从offset开始读取。
由于日志本身固有的特性,记录从左向右开始顺序插入,也就意味着左边的记录相较于右边的记录“更老”, 也就是说我们可以不用依赖于系统时钟,这个特性对于分布式系统来说相当重要。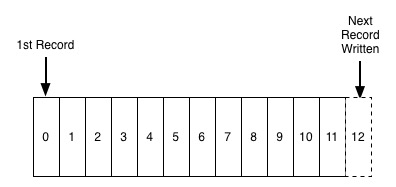
日志是什么时候出现已经无从得知,可能是概念上来讲太简单。在数据库领域中日志更多的是用于在系统crash的时候同步数据以及索引等,例如mysql中的redo log,redo log是一种基于磁盘的数据结构,用于在系统挂掉的时候保证数据的正确性、完整性,也叫预写日志,例如在一个事物的执行过程中,首先会写redo log,然后才会应用实际的更改,这样当系统crash后恢复时就能够根据redo log进行重放从而恢复数据(在初始化的过程中,这个时候不会还没有客户端的连接)。日志也可以用于数据库主从之间的同步,因为本质上,数据库所有的操作记录都已经写入到了日志中,我们只要将日志同步到slave,并在slave重放就能够实现主从同步,这里也可以实现很多其他需要的组件,我们可以通过订阅redo log 从而拿到数据库所有的变更,从而实现个性化的业务逻辑,例如审计、缓存同步等等。
分布式系统服务本质上就是关于状态的变更,这里可以理解为状态机,两个独立的进程(不依赖于外部环境,例如系统时钟、外部接口等)给定一致的输入将会产生一致的输出并最终保持一致的状态,而日志由于其固有的顺序性并不依赖系统时钟,正好可以用来解决变更有序性的问题。
我们利用这个特性实现解决分布式系统中遇到的很多问题。例如RocketMQ中的备节点,主broker接收客户端的请求,并记录日志,然后实时同步到salve中,slave在本地重放,当master挂掉的时候,slave可以继续处理请求,例如拒绝写请求并继续处理读请求。日志中不仅仅可以记录数据,也可以直接记录操作,例如SQL语句。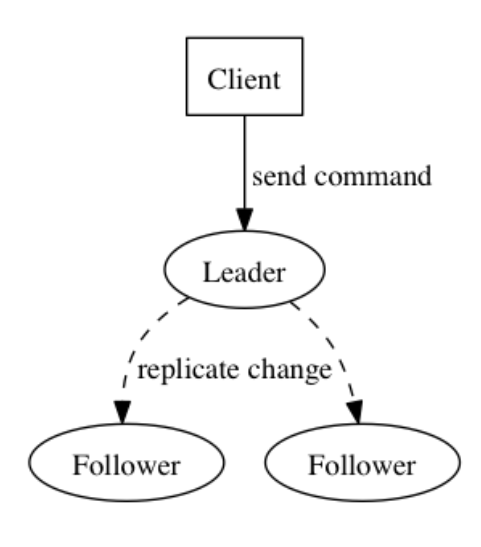
日志是解决一致性问题的关键数据结构,日志就像是操作序列,每一条记录代表一条指令,例如应用广泛的Paxos、Raft协议,都是基于日志构建起来的一致性协议。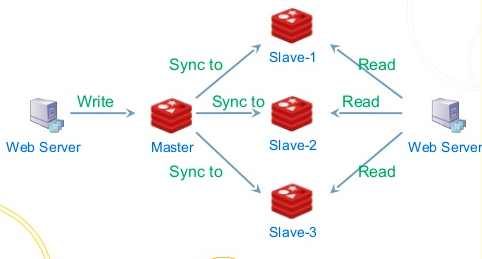
日志可以很方便的用于处理数据之间的流入流出,每一个数据源都可以产生自己的日志,这里数据源可以来自各个方面,例如某个事件流(页面点击、缓存刷新提醒、数据库binlog变更),我们可以将日志集中存储到一个集群中,订阅者可以根据offset来读取日志的每条记录,根据每条记录中的数据、操作应用自己的变更。
这里的日志可以理解为消息队列,消息队列可以起到异步解耦、限流的作用。为什么说解耦呢?因为对于消费者、生产者来说,两个角色的职责都很清晰,就负责生产消息、消费消息,而不用关心下游、上游是谁,不管是来数据库的变更日志、某个事件也好,对于某一方来说我根本不需要关心,我只需要关注自己感兴趣的日志以及日志中的每条记录。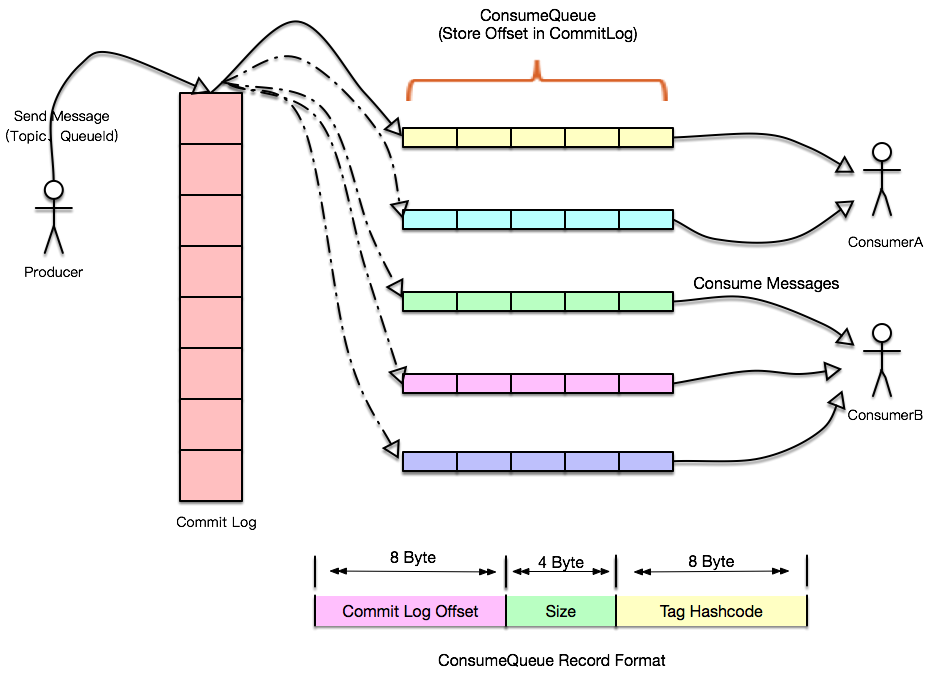
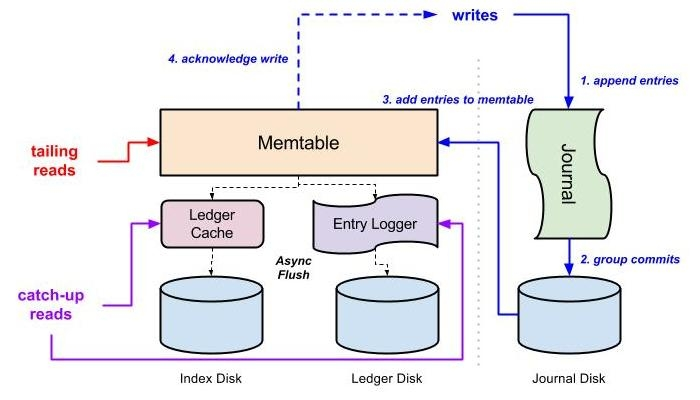
我们知道数据库的QPS是一定的,而上层应用一般可以横向扩容,这个时候如果到了双11这种请求突然的场景,数据库会吃不消,那么我们就可以引入消息队列,将每个队数据库的操作写到日志中,由另外一个应用专门负责消费这些日志记录并应用到数据库中,而且就算数据库挂了,当恢复的时候也可以从上次消息的位置继续处理(RocketMQ和Kafka都支持Exactly Once语义),这里即使生产者的速度异于消费者的速度也不会有影响,日志在这里起到了缓冲的作用,它可以将所有的记录存储到日志中,并定时同步到slave节点,这样消息的积压能力能够得到很好的提升,因为写日志都是有master节点处理,读请求这里分为两种,一种是tail-read,就是说消费速度能够跟得上写入速度的,这种读可以直接走缓存,而另一种也就是落后于写入请求的消费者,这种可以从slave节点读取,这样通过IO隔离以及操作系统自带的一些文件策略,例如pagecache、缓存预读等,性能可以得到很大的提升。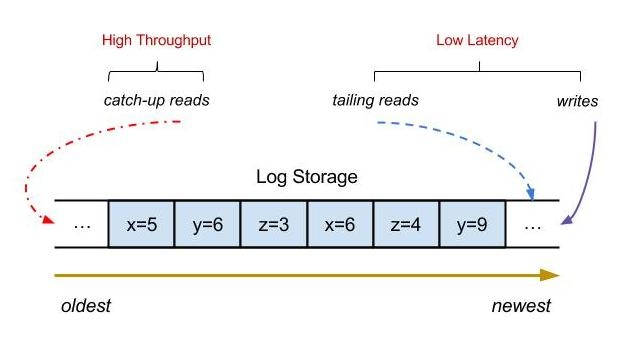
分布式系统中可横向扩展是一个相当重要的特性,加机器能解决的问题都不是问题。那么如何实现一个能够实现横向扩展的消息队列呢? 假如我们有一个单机的消息队列,随着topic数目的上升,IO、CPU、带宽等都会逐渐成为瓶颈,性能会慢慢下降,那么这里如何进行性能优化呢?
日志在分布式系统中扮演了很重要的角色,是理解分布式系统各个组件的关键,随着理解的深入,我们发现很多分布式中间件都是基于日志进行构建的,例如Zookeeper、HDFS、Kafka、RocketMQ、Google Spanner等等,甚至于数据库,例如Redis、MySQL等等,其master-slave都是基于日志同步的方式,依赖共享的日志系统,我们可以实现很多系统: 节点间数据同步、并发更新数据顺序问题(一致性问题)、持久性(系统crash时能够通过其他节点继续提供服务)、分布式锁服务等等,相信慢慢的通过实践、以及大量的论文阅读之后,一定会有更深层次的理解。
以上就是分布式系统的核心——日志的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 360
360























