
随着 Sora 发布成功,视频 DiT 模型引起了广泛关注和讨论。设计稳定的超大规模神经网络一直是视觉生成领域研究的重点。DiT 模型的成功为图像生成的规模化带来了新的可能性。
然而,由于视频数据的高度结构化和复杂性,将 DiT 扩展到视频生成领域是一项具有挑战性的任务。一支由上海人工智能实验室的研究团队和其他机构联合组成的团队,通过大规模的实验回答了这一问题。
去年11月,该团队已经发布了一款名为Latte的自研模型,其技术与Sora有相似之处。Latte是全球首个开源文生视频DiT,受到了广泛关注。许多开源框架如Open-Sora Plan (PKU)和Open-Sora (ColossalAI)都在使用和参考Latte的模型设计。

先来看下Latte的视频生成效果。

总的来说,Latte包含两个关键模块:预先训练的VAE和视频DiT。在预先训练的VAE中,编码器负责将视频逐帧从像素空间压缩到潜在空间,而视频DiT则负责提取token并进行时空建模以对潜在表征进行处理,最后,VAE解码器将特征映射回像素空间以生成视频。为了获得最佳的视频质量,研究者专注于Latte设计中的两个重要方面,即视频DiT模型的整体结构设计和模型训练的最佳实践细节。
(1)latte 整体模型结构设计探究
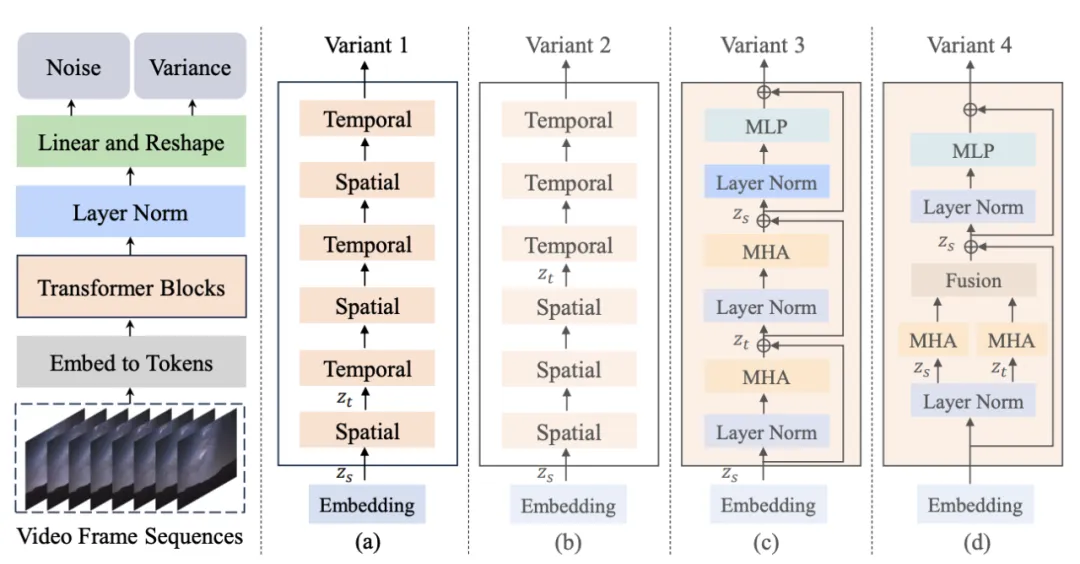
图 1. Latte 模型结构及其变体
作者提出了 4 种不同的 Latte 变体 (图 1),从时空注意力机制的角度设计了两种 Transformer 模块,同时在每种模块中分别研究了两种变体(Variant):
1. 单注意力机制模块,每个模块中只包含时间或者空间注意力。
2. 多注意力机制模块,每个模块中同时包含时间与空间注意力机制 (Open-sora所参考变体)。
实验表明 (图 2),通过对 4 种模型变体设置相同的参数量,变体 4 相较于其他三种变体在 FLOPS 上有着明显的差异,因此 FVD 上也相对最高,其他 3 种变体总体性能类似,变体 1 取得了最优异的性能,作者计划未来在大规模的数据上做更加细致的讨论。
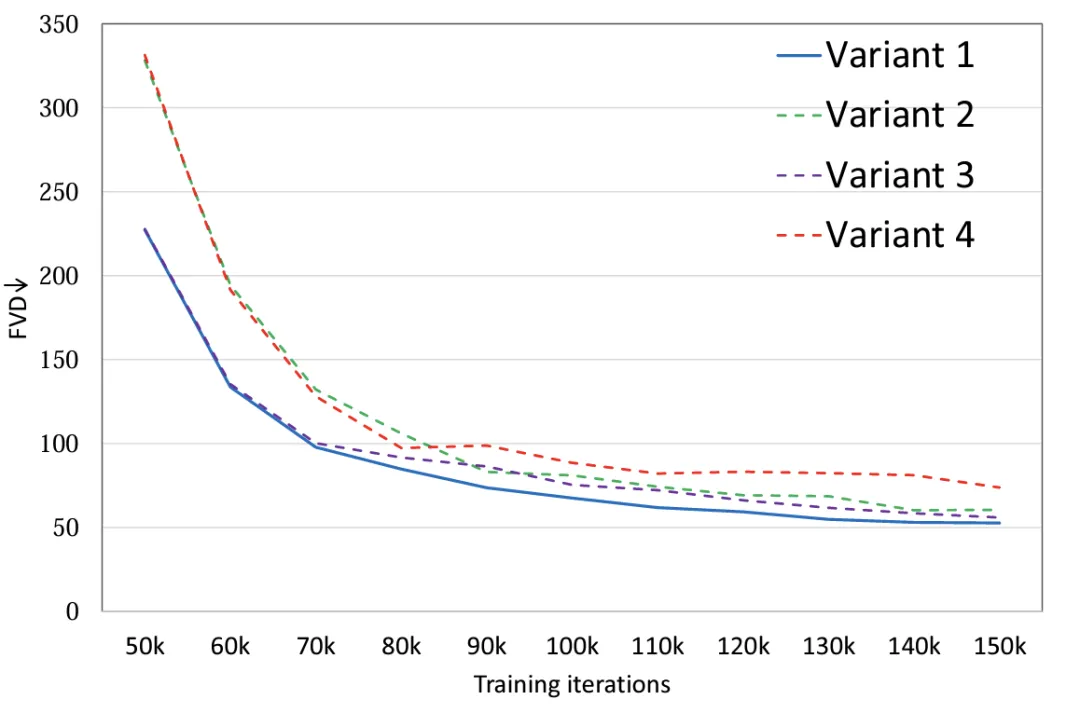
图 2. 模型结构 FVD
(2)Latte 模型与训练细节的最优设计探究(The best practices)
除了模型总体结构设计,作者还探究了其他模型与训练中影响生成效果的因素。
1.Token 提取:探究了单帧 token(a)和时空 token(b)两种方式,前者只在空间层面压缩 token,后者同时压缩时空信息。实验显示单帧 token 要优于时空 token(图 4)。与 Sora 进行比较,作者猜测 Sora 提出的时空 token 是通过视频 VAE 进行了时间维度的预压缩,而在隐空间上与 Latte 的设计类似都只进行了单帧 token 的处理。
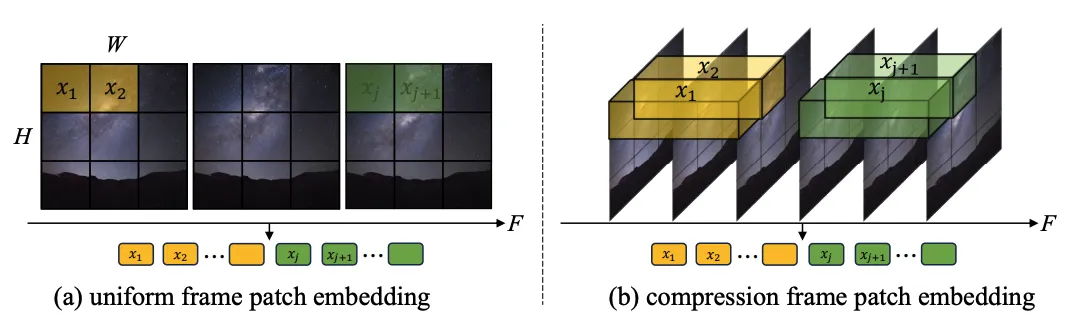
图 3. Token 提取方式,(a) 单帧 token 和 (b) 时空 token
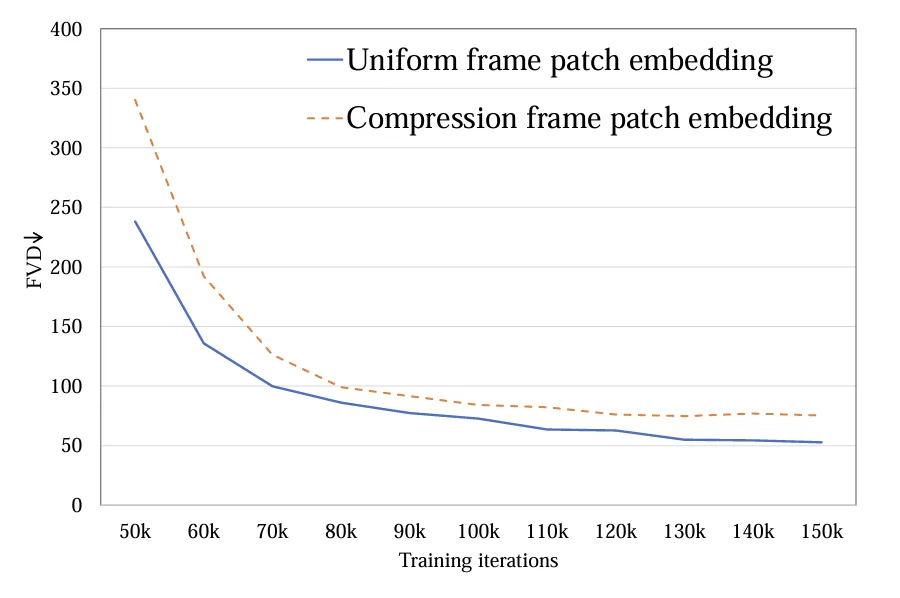
图 4. Token 提取 FVD
2. 条件注入模式:探究了(a)S-AdaLN 和(b)all tokens 两种方式 (图 5)。S-AdaLN 通过 MLP 将条件信息转换为归一化中的变量注入到模型中。All token 形式将所有条件转化为统一的 token 作为模型的输入。实验证明,S-AdaLN 的方式相较于 all token 对于获得高质量的结果更加有效 (图 6)。原因是,S-AdaLN 可以使信息被直接注入到每一个模块。而 all token 需要将条件信息从输入逐层传递到最后,存在着信息流动过程中的损失。
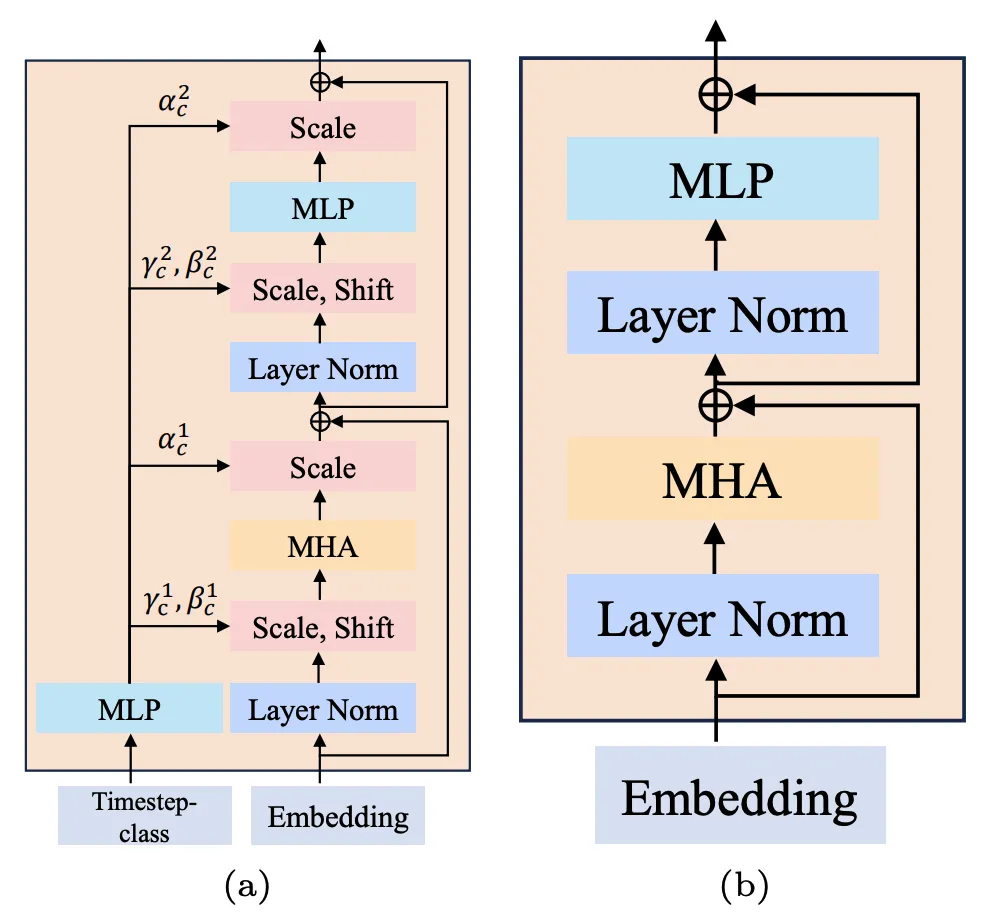
图 5. (a) S-AdaLN 和 (b) all tokens。
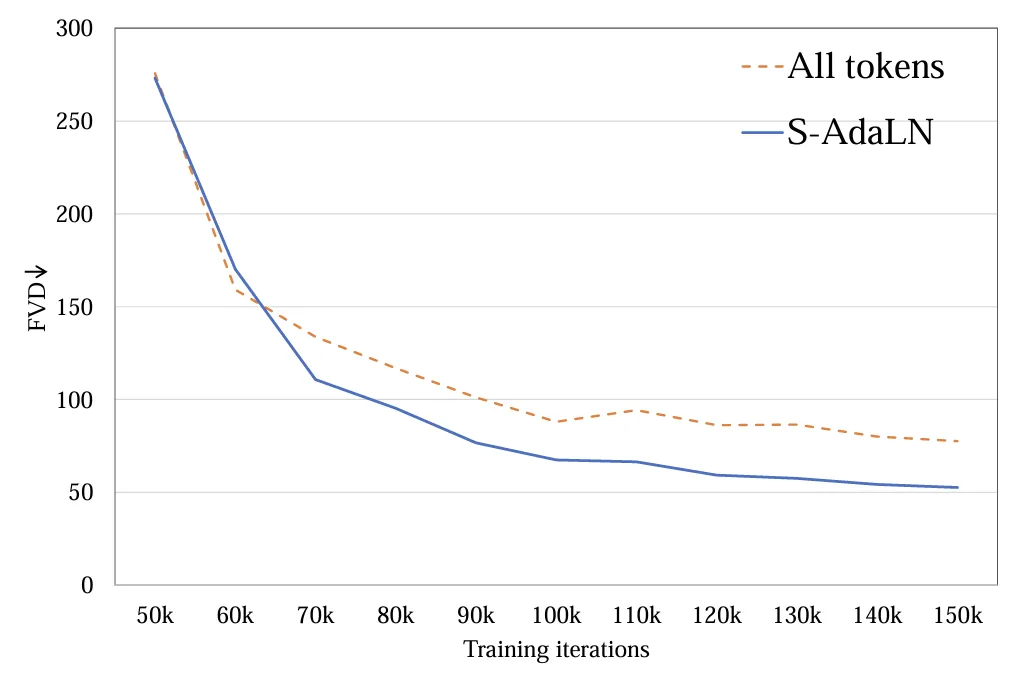
图 6. 条件注入方式 FVD
3. 时空位置编码:探究了绝对位置编码与相对位置编码。不同的位置编码对最后视频质量影响很小 (图 7)。由于生成时长较短,位置编码的不同不足以影响视频质量,对于长视频生成,这一因素需要被重新考虑。
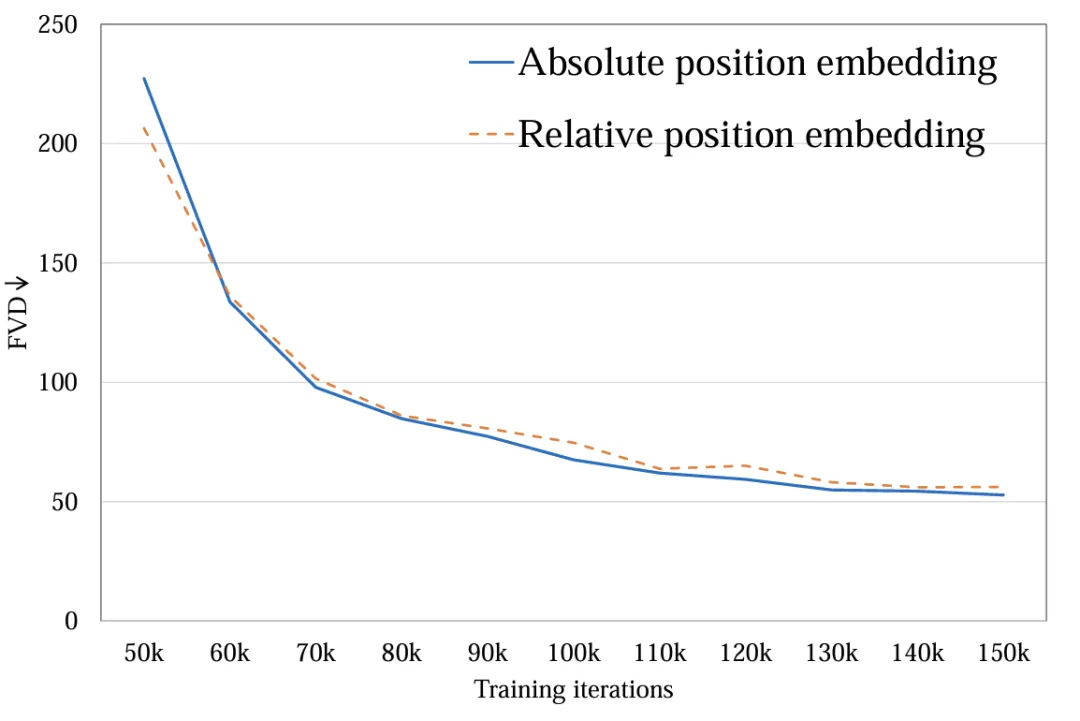
图 7. 位置编码方式 FVD
4. 模型初始化:探究使用 ImageNet 预训练参数初始化对模型性能的影响。实验表明,使用 ImageNet 初始化的模型具有较快的收敛速度,然而,随着训练的进行,随机初始化的模型却取得了较好的结果 (图 8)。可能的原因在于 ImageNet 与训练集 FaceForensics 存在着比较大的分布差异,因此未能对模型的最终结果起到促进作用。而对于文生视频任务而言,该结论需要被重新考虑。在通用数据集的分布上,图像与视频的内容空间分布相似,使用预训练 T2I 模型对于 T2V 可以起到极大的促进作用。
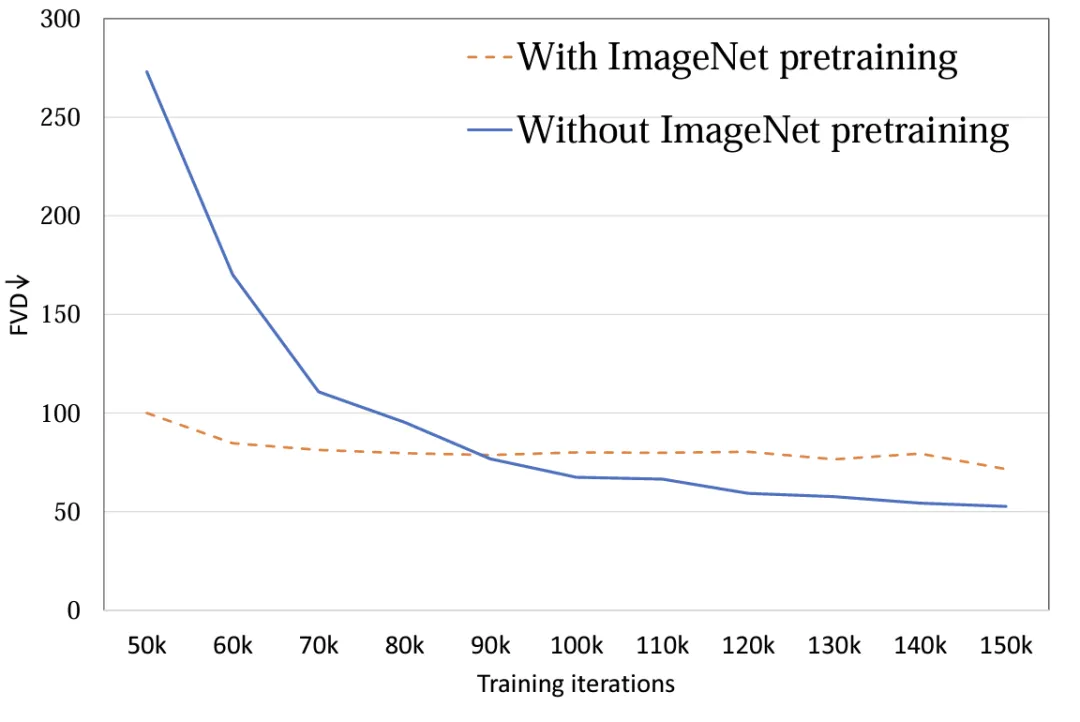
图 8. 初始化参数 FVD
5. 图像视频联合训练:将视频与图像压缩为统一 token 进行联合训练,视频 token 负责优化全部参数,图像 token 只负责优化空间参数。联合训练对于最终的结果有着显著的提升 (表 2 和表 3),无论是图片 FID,还是视频 FVD,通过联合训练都得到了降低,该结果与基于 UNet 的框架 [2][3] 是一致的。
6. 模型尺寸:探究了 4 种不同的模型尺寸,S,B,L 和 XL (表 1)。扩大视频 DiT 规模对于提高生成样本质量有着显著的帮助 (图 9)。该结论也证明了在视频扩散模型中使用 Transformer 结构对于后续 scaling up 的正确性。
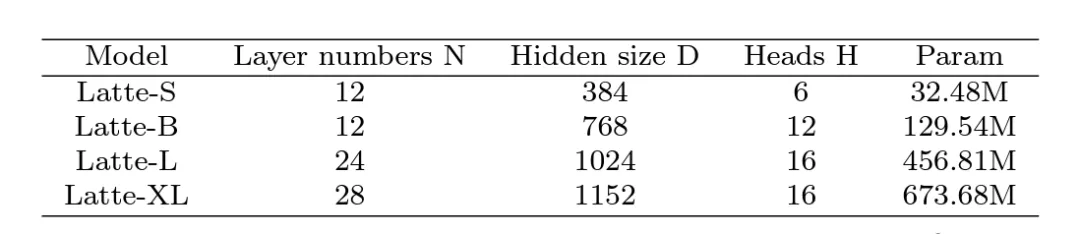
表 1. Latte 不同尺寸模型规模
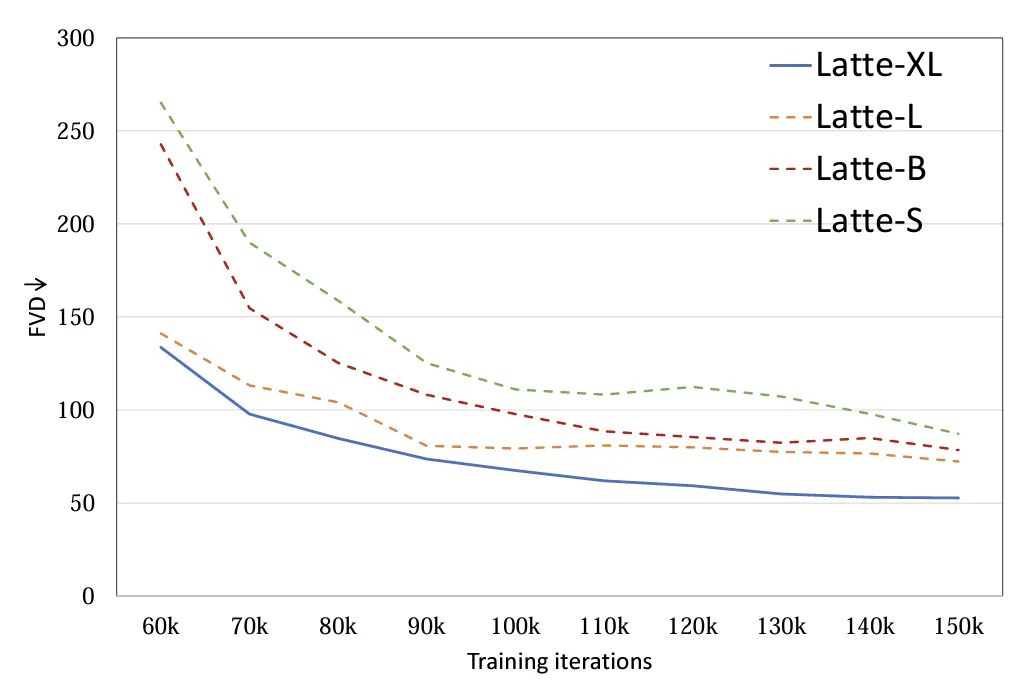
图 9. 模型尺寸 FVD
作者分别在 4 个学术数据集(FaceForensics,TaichiHD,SkyTimelapse 以及 UCF101)进行了训练。定性与定量(表 2 和表 3)结果显示 Latte 均取得了最好的性能,由此可以证明模型整体设计是具有优异性的。
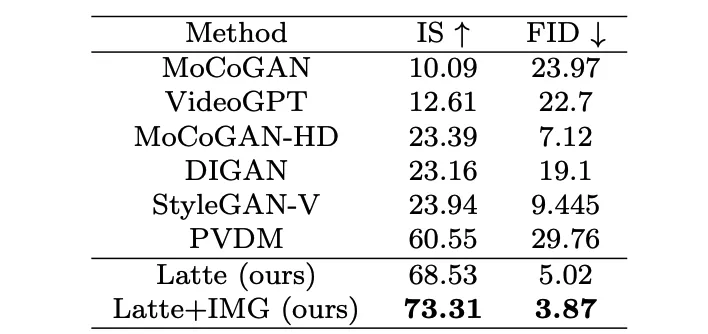
表 2. UCF101 图片质量评估
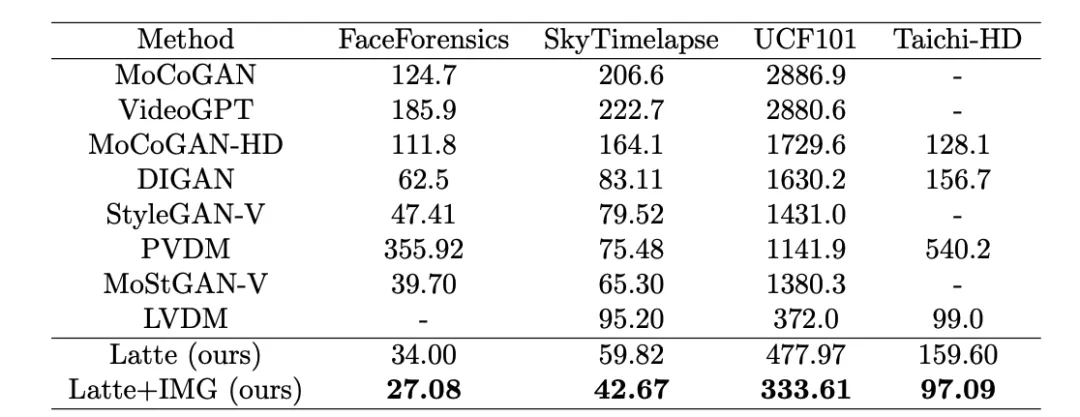
表 3. Latte 与 SoTA 视频质量评估
文生视频扩展
为了进一步证明 Latte 的通用性能,作者将 Latte 扩展到了文生视频任务,利用预训练 PixArt-alpha [4] 模型作为空间参数初始化,按照最优设计的原则,在经过一段时间的训练之后,Latte 已经初步具备了文生视频的能力。后续计划通过扩大规模验证 Latte 生成能力的上限。
Latte 作为全世界首个开源文生视频 DiT,已经取得了很有前景的结果,但由于计算资源的巨大差异,在生成清晰度,流畅度上以及时长上与 Sora 相比还具有不小的差距。团队欢迎并在积极寻求各种合作,希望通过开源的力量,打造出性能卓越的自主研发大规模通用视频生成模型。
以上就是详解Latte:去年底上线的全球首个开源文生视频DiT的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 197
197























