
之前已经介绍过了schema的作用了,这一篇会把rule和server一起介绍~
首先是rule,在这个文件里面会详细的制定多种分片的规则,这次只抽出一些使用率比较高的方法,先上配置文件的内容

可以简单看一下,在截图的上半部分描述的是rule的定义,在下半部分,是rule对应的实际切分规则,这里总工介绍下面四种切分方式~murmur已坑~
-------------------------------------------------------------------------------------------Hash-int---------------------------------------------------------------------------------
先看hash-int,在这一条切分规则的下面,有一个mapfile,这代表着,这个切分规则是根据partition-hash-int的内容来决定的,那么看一下这个文本文件
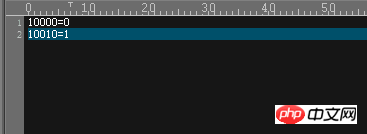
很简单的内容,这代表着切分使用的基准列里面,值为10000的时候,放在第一个DN里面(dn1),值为10010的时候,放在第二个DN里面(dn2)
可以看一下实际效果

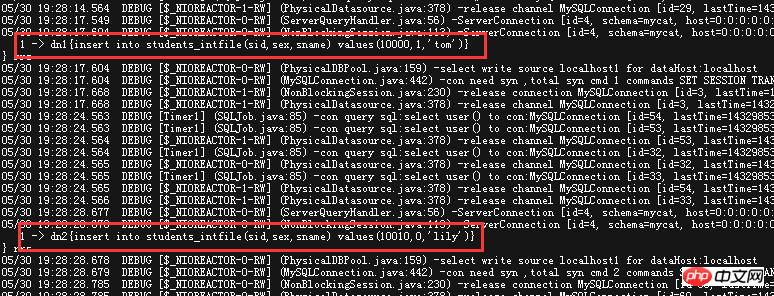
看一下MyCAT的Debug日志,这两条语句被分配到了dn1和dn2上面,数据库里面也插入了相对应的数据
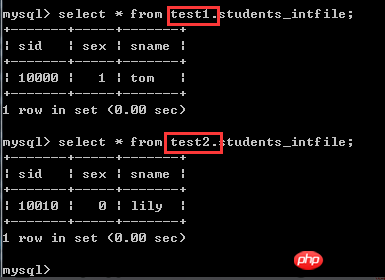
那么~问题来了(挖掘机滚粗~),如果插入的数据中,基准列的取值不是这个文件里面写明的值,会是什么效果?
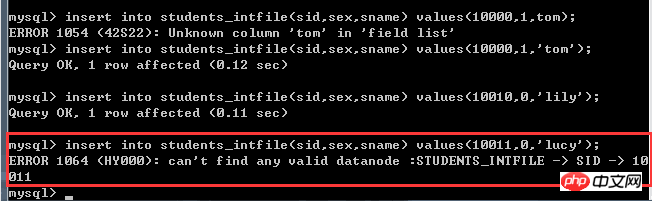
直截了当的报错了~
好了,hash-int的这种切分规则,大体上可以理解为枚举分区,会比较适合于取值固定的场合,比如说性别(0,1),省份(固定值,短时间不会收复日本省吧~),渠道商
or 各种平台的ID
而且,用逗号分隔可以把多个值放在一个分区里面,所以可以根据实际的数据量/流量/访问量来综合制定切分策略;
缺点:毕竟不是全能战士╮(╯_╰)╭
-------------------------------------------------------------------------------------------range-long---------------------------------------------------------------------------------
第二种切分方式,range-long,仔细一看的话,和hash-int是比较像的,也是由特定的文件来决定切分策略,所以还是去看一下文件的内容
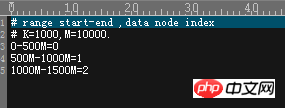
从文件内容可以看出,这是一种范围切分的方式,制定基准列的取值范围,然后把这一范围的所有数据都放到一个DN上面,这种方式和hash-int基本一致,就不截图了(懒癌晚期,时间不够了!)
这种切分策略,个人感觉在业务数据库里面的使用场景会少一些,因为这种切分方式需要预定好整体的数量,这就决定了那种无限增长的数据不能用这个,毕竟要改动这个切分策略会很麻烦
真要用起来,感觉也就对自增主键用,然后按照一定的数量来均匀切分,比如那种一天固定X条数据的业务(温度采集?数据采集?之类的情况),然后提前建好多个DN(库)。
当然,也存在一种潜在的问题,如果在短时间发生海量的顺序插入操作,而每一个DN(分库)设定的数量比较高(比如说一个DN设定的放1000W条数据),那么在这个时候,会出现某一个DN(分库)IO压力非常高,而其他几个DN(分库)完全没有IO操作,就会出现类似于DB中常见的热块/热盘的现象,而MySQL经常用自增主键,所以使得MySQL的表出现大量“顺序”插入的机会会多很多。
--------------------------------------------------------------------------------------------mod-long-----------------------------------------------------------------------------------
mod-long,从mod来看这应该是一种取余数的方法,来看一下具体配置的信息

count=4,这是代表着总共把数据切分成四份,一般是和具体的DN数量对应,从而达到把数据均匀的分布在四个DN上(当然,count
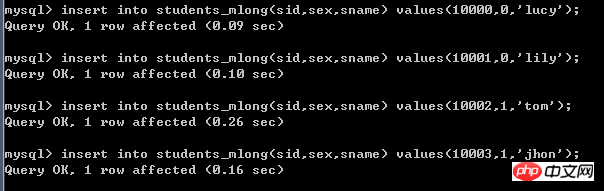
看一下MyCAT的Debug日志,看看MyCAT是如何处理的
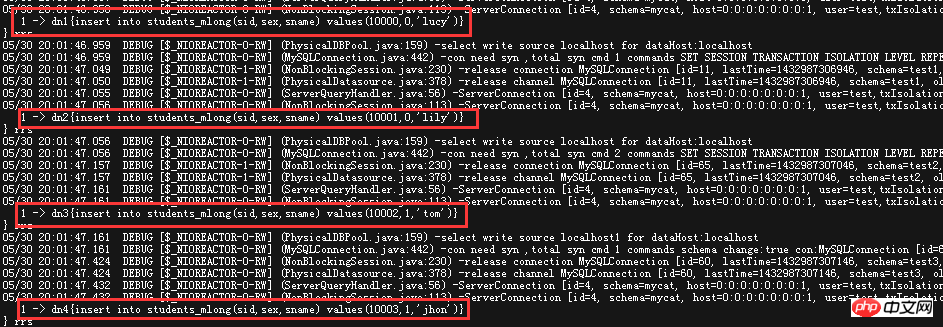
采用这种取余数的方式时,这四条数据分别插入了四个DN(库),而且可以看到,顺序插入时,数据是被均匀的分散在多个DN(库)上面
相比较于上面的range的方法,这种切分策略会更好的分散数据库写的压力,但是问题也很明显,一旦出现了范围查询,就需要MyCAT去合并结果,当数据量偏高的时候,这种跨库查询+合并结果消耗的时间有可能会增加很多,尤其是还出现了order
by的时候。
所以这种切分策略会比较适合于单点查询的情景,比如说.....我也不知道......真的不知道,也许在银行,查询个人账户信息的时候,一些和用户信息的表可以做好冗余,然后利用这种方式来提供更为高效的查询(毕竟银行的用户数量多,恩恩~)
--------------------------------------------------------------------------------partition-by-long----------------------------------------------------------------------------------
partition-by-long,处于range-long和mod-long之间的一个略微折中的划分策略,具体切分形势依照如下描述:
以1024为一个单位,每个DN存放partitionLength数量的数据,且,partitionCount x partitionLength=1024
看起来有点难以理解,形象点描述的话,以partitionCount(4) x partitionLength(256)为例,sid%1024=0-255的放在DN1,256-511的放在DN2,以此类推
试着以128为偏移值插入了八条数据,直接看MyCAT的日志
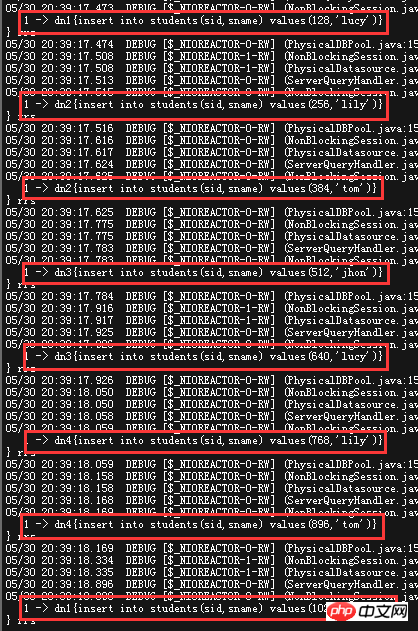
可以看到,八条数据均匀的分布在这四个DN里面~
值得一提的是,这种切分策略也支持非均匀分布~实在是测不动了,盗图两张~


这两张图基本上也说明白了这种非均匀分布的划分策略,重点还是在2x256+1x512=1024上面~
这种划分策略在range-long和mod-long之间取了一个折中点,同时,也还算是比较灵活,可以根据不同的情况进行非均匀划分,实际上能应用的场景会稍微多一点吧,或者说,不少场景都能用一用,相对减少了跨DN的情形,又把数据比较均匀的切分开来了,单点查询也不会太慢。
-----------------------------------------------------------------------------------写在最后-------------------------------------------------------------------------------------
其实MyCAT支持的切分方式还有不少,比如说按照时间的切分策略,可以按月,按天切分等,在这里也没办法把所有的策略都放上来,见谅了o( ̄ヘ ̄o#)
实际上从个人的观点来看,时间的切分依照数据库本身的分区策略来分也没什么问题,半年度,季度的数据也还是会需要查询的....PS: _(:з」∠)_真不是懒...
可以说,MyCAT的分库分表的重点,基本全部在这个rule里面体现了,表要不要分,表的数据怎么切分,都是需要根据实际业务来决定,充分根据业务的特点去决定最合适的划分策略~
以上就是MySQL分布式集群之MyCAT(三)rule的详细分析(图文)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 635
635























