
给定两个二叉搜索树的根节点。如果两个二进制搜索树是相同的,则打印1,否则打印0.如果两个树在结构上相同且节点具有相同的值,则它们是相同的。
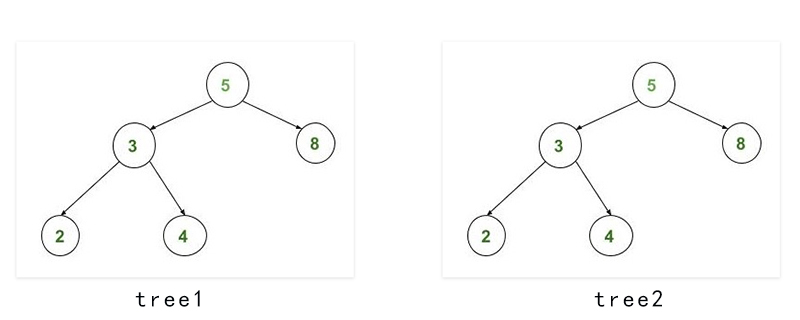
在上面的图像中,tree1和tree2都是相同的。
为了确定两棵树是否相同,我们需要同时遍历两棵树,并且在遍历时我们需要比较树木的数据和子节点。
以下是逐步算法,以检查两个BST是否相同:
1.如果两棵树都是空的,则返回1。
立即学习“C++免费学习笔记(深入)”;
2.否则,如果两棵树都是非空的
-检查根节点的数据(tree1-> data == tree2-> data)
-递归检查左子树,即调用sameTree(tree1-> left_subtree,tree2-> left_subtree)
-递归检查右子树,即调用sameTree(tree1-> right_subtree,tree2-> right_subtree)
-如果上述三个步骤中返回的值为true,则返回1。
3.否则返回0(一个是空的而另一个不是)。
以下是上述方法的实现:
// c++程序检查两个bst是否相同
#include <iostream>
using namespace std;
// BST节点
struct Node {
int data;
struct Node* left;
struct Node* right;
};
// 创建新节点的实用程序函数
struct Node* newNode(int data)
{
struct Node* node = (struct Node*)
malloc(sizeof(struct Node));
node->data = data;
node->left = NULL;
node->right = NULL;
return node;
}
//函数执行顺序遍历
void inorder(Node* root)
{
if (root == NULL)
return;
inorder(root->left);
cout << root->data << " ";
inorder(root->right);
}
// 函数检查两个bst是否相同
int isIdentical(Node* root1, Node* root2)
{
// 检查这两棵树是否都是空的
if (root1 == NULL && root2 == NULL)
return 1;
// 如果树中的任意一个为非空,另一个为空,则返回false
else if (root1 != NULL && root2 == NULL)
return 0;
else if (root1 == NULL && root2 != NULL)
return 0;
else {
// 检查两个树的当前数据是否相等,并递归地检查左子树和右子树
if (root1->data == root2->data && isIdentical(root1->left, root2->left)
&& isIdentical(root1->right, root2->right))
return 1;
else
return 0;
}
}
// 驱动代码
int main()
{
struct Node* root1 = newNode(5);
struct Node* root2 = newNode(5);
root1->left = newNode(3);
root1->right = newNode(8);
root1->left->left = newNode(2);
root1->left->right = newNode(4);
root2->left = newNode(3);
root2->right = newNode(8);
root2->left->left = newNode(2);
root2->left->right = newNode(4);
if (isIdentical(root1, root2))
cout << "Both BSTs are identical";
else
cout << "BSTs are not identical";
return 0;
}输出:
Both BSTs are identical
本篇文章就是关于检查两个二进制搜索树是否相同的方法介绍,希望对需要的朋友有所帮助!
以上就是c++检查两个二进制搜索树是否相同的详细内容,更多请关注php中文网其它相关文章!

c++怎么学习?c++怎么入门?c++在哪学?c++怎么学才快?不用担心,这里为大家提供了c++速学教程(入门到精通),有需要的小伙伴保存下载就能学习啦!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 959
959






















